
Research
My research focuses on learning robust, generalizable representations in machine learning systems, especially in settings with limited supervision, cross-modal inputs, or distribution shifts. I am especially interested in how structure emerges from self-supervised objectives, and how generative models can be analyzed and repurposed for safety and interpretability.
Publications
- EMBC 2025 (Accepted) – Impact of Noise on Deep Learning-Based Pseudo-Online Gesture Recognition with High-Density EMG. Mansour Taleshi, Dennis Yeung, Minh Dinh Trong, Francesco Negro, Stéphane Deny, Ivan Vujaklija.
Privacy preserving
Under the supervisor of Professor SouYoung Jin at Dartmouth, my research focuses on privacy-preserving techniques for training multimodal models on video data. I develop generative pipelines that modify audiovisual content to remove identifiable traits, such as faces, voices, or contextual personal cues, while preserving semantic and temporal coherence. This allows models to learn from rich, real-world video data without compromising individual privacy.
Representation Learning
As a research assistant at Aalto University’s BRAIN Lab under Prof. Stephane Deny, I investigated self-supervised learning and invariance in biological and artificial vision systems. I contributed to projects exploring feature disentanglement, local equivariance, and learning from natural scenes without labels.
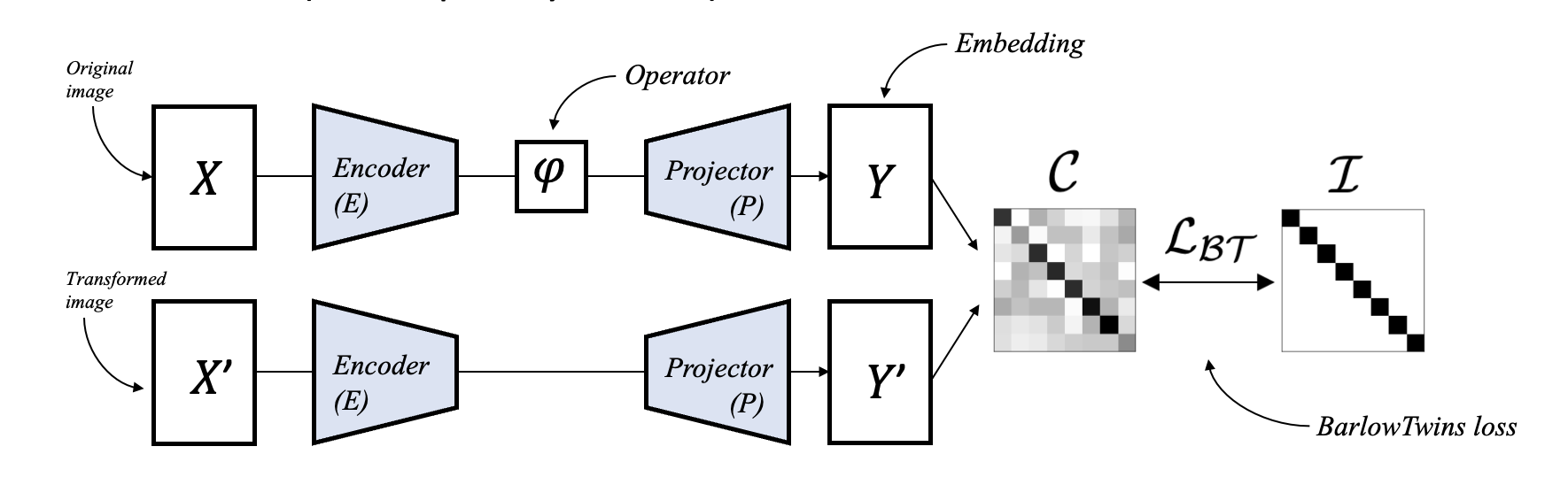 Self-supervised model utilizing learnable VAE and operators for reverting distortion.
Self-supervised model utilizing learnable VAE and operators for reverting distortion.
Extension to process Electromyography (EMG) signal, offering a GUI for real-time EMG visualization and motion classification: 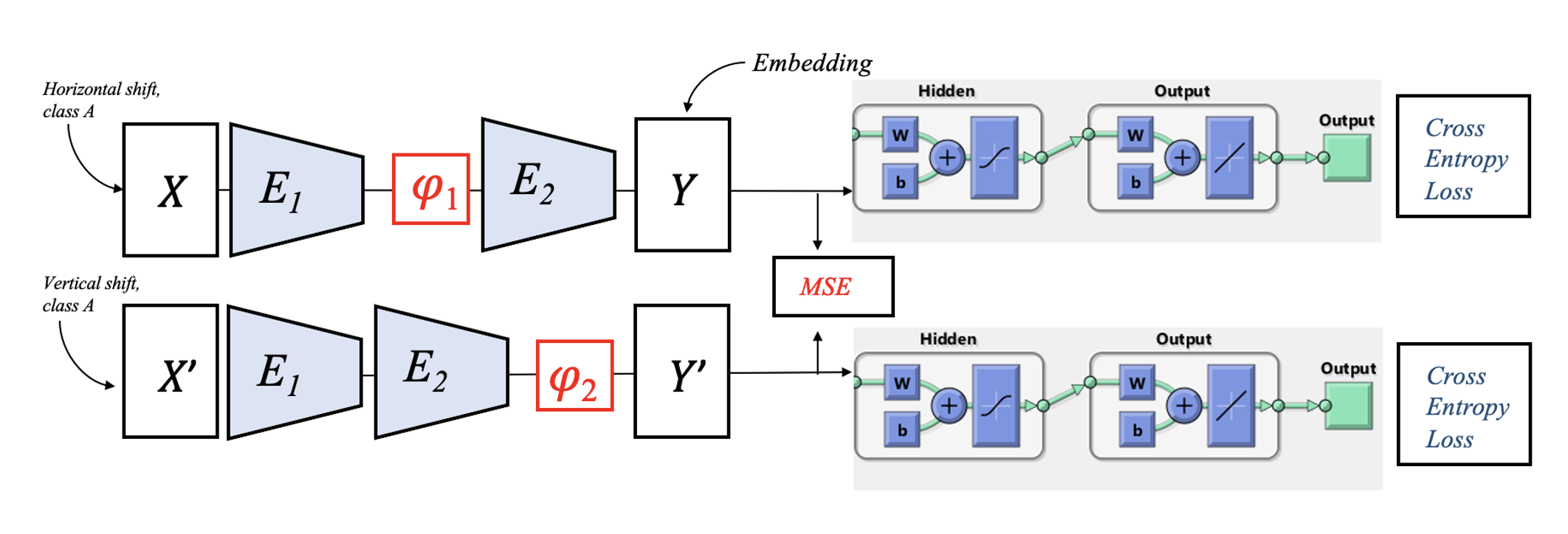
- Funding: Grant for Activity Funding, March 2023
Scene Representation
My Bachelor’s thesis, supervised by Prof. Alexander Ilin, focused on scene representation using neural fields. I implemented object-centric architectures to encode spatial and structural information from 2D observations, contributing to ongoing research in compositional generalization.
Title: Recent Advances in Scene Representation. PDF. Aalto Archive (with credentials).
- Supervisor: Professor Alexander Ilin
- Abstract:
[…] current models have limitations in generalizability, processing speed, and noise robustness, posing possibilities for further improvements in the future. This thesis, as a state-of-the-art review, offers a cohesive summary of recently proposed methodologies for representing and utilizing an understanding of 3D scenes from 2D observations, with a concentration on variants of two highly potential techniques: neural radiance field (NeRF) and scene representation transformer (SRT).
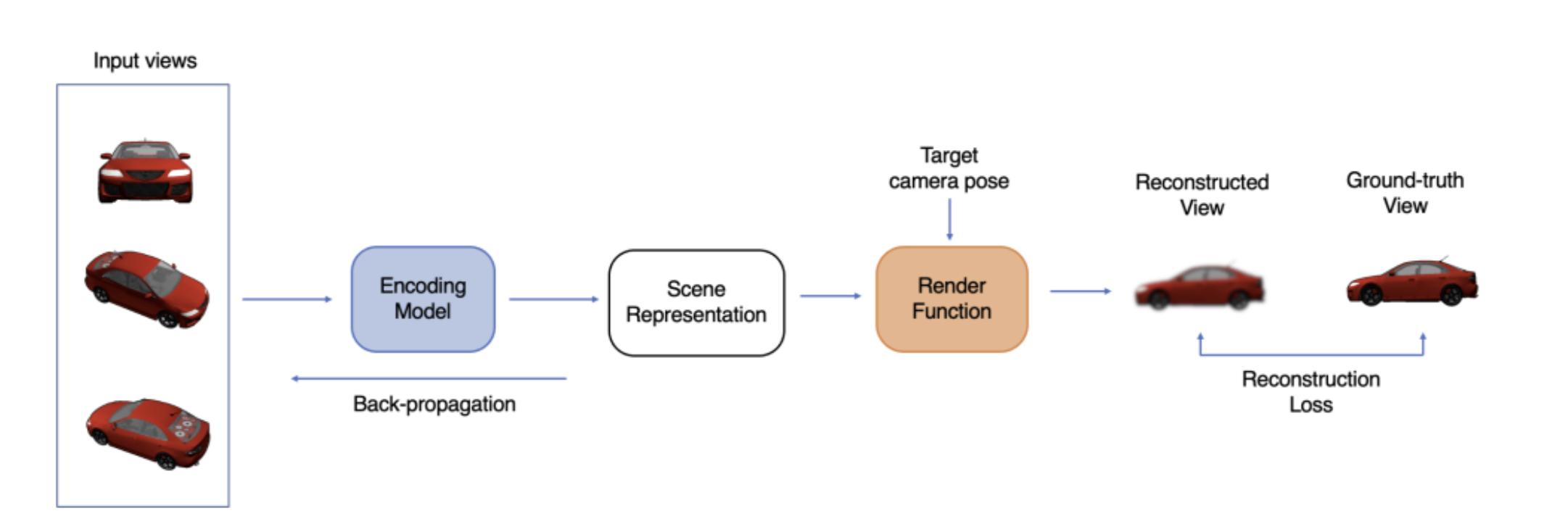 General pipeline for training a scene representation. An encoding model processes input views to obtain a scene representation, which is then used for rendering a predicted view at a target pose. The reconstruction loss between the predicted and ground-truth views is employed for backpropagation to optimize the module parameters.
General pipeline for training a scene representation. An encoding model processes input views to obtain a scene representation, which is then used for rendering a predicted view at a target pose. The reconstruction loss between the predicted and ground-truth views is employed for backpropagation to optimize the module parameters.
Diffusion-Based Deepfake Detection
As part of a research exchange at EPFL, I worked in the Professor Sabine Süsstrunk’s Image and Visual Representation Lab (IVRL) under the supervision of her PhD students Yufan Ren and Peter Grönquist. My research focused on identifying synthetic visual content by analyzing structural patterns and generation dynamics present in visual data. I studied how these signals degrade or persist under real-world conditions such as compression artifacts, partial occlusion, and mismatch between training and target distributions.